The HBM Fragmentation Problem in LLM inference
HBM is the tightest physical resource in modern large-model serving. Compute keeps getting faster, tensor cores keep widening, and model stacks keep getting more heterogeneous, but the serving system still has to fit the working set inside a fixed number of HBM stacks. On an H100, that means 80GB of HBM for everything that wants accelerator-local residency: model weights or weight shards, KV-cache blocks, expert weights in an MoE router, activation buffers, temporary scratch allocations, and whatever the serving runtime needs to keep around between kernels. In 2025 and 2026, this is no longer a niche systems concern. It is the constraint that determines how much useful concurrency you can extract from a GPU.
Consider long-context inference. A single 128K-token session on a model in the Llama-3.1-70B class can easily drive KV-cache footprint into the tens of gigabytes. Forty gigabytes is not a crazy number anymore; it is an expected operating point for serious long-context serving. Now layer multiple concurrent requests on top of that, each with different sequence lengths and different decode progress. Add expert weight movement for MoE models. Add activation buffers for prefill bursts, speculative decoding, tool calls, or vision tokens. The problem is not merely that HBM fills up. The problem is that it fills up in chunks that are allocated and freed on very different time scales, and the resulting free space stops being contiguous.
In practice, modern inference stacks have three broad classes of HBM residents. First, there are KV-cache blocks: large, session-scoped objects whose reuse depends on whether the request is still alive and whether the next decode step will revisit that sequence. Second, there are expert weights in MoE models: large objects that may be touched for a burst of routed tokens, then go cold, then become hot again depending on the traffic mix. Third, there are activation buffers: comparatively small, very short-lived allocations with high churn. Each class places a different kind of pressure on HBM. KV-cache is bulky and sticky. Experts are bursty and skewed. Activations are noisy. Put them together and you get the worst possible allocator environment: mixed sizes, mixed lifetimes, and mixed reuse distributions.
This is where it is important to separate internal fragmentation from external fragmentation. Systems like vLLM’s PagedAttention are an excellent answer to internal fragmentation inside the logical KV-cache block allocator. If you allocate attention state in pages of 16 to 128 tokens, you avoid wasting a giant monolithic slab for every sequence. That is a real win. But it does not eliminate the physical fragmentation problem in HBM itself. You can still end up with a pile of free pages distributed across the address space in a way that prevents a larger contiguous allocation from succeeding. Internal waste inside a logical block may be low while physical external fragmentation remains high.
The distinction matters because allocators fail on contiguity, not on accounting. If 8GB is free but the largest free extent is only 48MB, then your next 2GB resident simply does not fit. The serving system may still report “plenty of free memory,” but that free memory is operationally useless for large objects. This is exactly the pathology that shows up in the fragmentation literature around KV-cache movement. The Strata paper from MLSys 2025 makes the point from a transfer-path angle: fragmentation in the cache layout turns what should be large saturating transfers into many small transfers that leave PCIe bandwidth on the table. That observation is completely consistent with what happens inside HBM as well. Fragmentation destroys the shape of memory, not just the quantity.
Now look at the baseline policy most systems still reach for under pressure: LRU. LRU is attractive because it is simple and because it often works “well enough” when working sets are smooth and reuse is mostly monotone. But LRU has no forecast of future reuse. It only knows what happened in the past. In an MoE model, an expert last used 50ms ago may be needed again 5ms from now because the router is skewed and the input stream is correlated. LRU cannot represent that. It interprets old recency as low value even when actual reuse probability is high. The result is classic churn: evict, reload, evict, reload. Every reload means another fill into HBM, another placement decision, and potentially another transfer from a slower tier such as DRAM.
That is the systems failure mode this work is aimed at. I do not want a policy that is merely more “adaptive” in a vague sense. I want a policy that answers a concrete question at the HBM residency layer: can we do better than LRU by incorporating a probabilistic reuse forecast into the admission and eviction decision, while keeping the system deterministic enough for production deployment? Marconi, also at MLSys 2025, is the closest conceptual neighbor because it uses forecast-based admission for prefix caching in hybrid LLM systems. But Marconi operates at the semantic cache layer. The HBM Fragmentation Guard sits lower, at physical HBM residency. That makes it orthogonal to both semantic prefix reuse systems and transfer-layer approaches like Strata.
Confidence-gated HBM hysteresis
The first mechanism is the confidence gate itself. Every object that can potentially reside in HBM is associated with a reuse forecast expressed as mu and sigma. You can interpret that pair as a compact representation of both belief and uncertainty about near-term reuse. Some objects are obvious residents: a decode-hot KV block that will almost certainly be touched again in the next few steps, or a hot expert under a skewed routing distribution. Others are obvious non-residents: a one-shot activation buffer or a checkpoint-write touch that is unlikely to recur. The policy needs to separate those classes without overreacting to noise.
Admission is therefore conservative. Formally, the default rule is admit if mu >= confidence_floor AND occupancy < LB_threshold. In the simulator, the confidence floor is typically 0.70 and the lower occupancy threshold is around 0.65. This means that even a promising object is not pre-admitted if HBM is already in a crowded regime. The policy only speculates when both the forecast and the instantaneous occupancy say it is safe to do so.
Eviction is intentionally asymmetric. Once occupancy rises above the upper bound, the policy begins evicting the lowest-confidence resident first: evict lowest(mu) while occupancy > UB_threshold. The upper bound is set above the lower bound, which creates a hysteresis band. That band is what prevents the policy from oscillating around a single threshold. Without it, a new resident can push occupancy over the line, immediately trigger another eviction, drop occupancy back under the line, then become eligible for re-admission. Anyone who has debugged a bad cache policy has seen this movie before.
This is where LRU looks especially weak. LRU is effectively assuming that the least recently used object has reuse probability zero relative to the rest of the resident set. That assumption is often wrong for model-serving workloads. A KV block that has not been touched for one scheduling slice may still be far more valuable than a freshly arrived activation buffer. A recently cold expert may still dominate the next routed microbatch. Once you admit that objects have distinct reuse distributions, LRU becomes a coarse proxy for a signal you could model directly.
The hysteresis band is also what makes confidence-gated control production-plausible rather than academically clever. A single threshold can score well on a narrow benchmark and still behave terribly under transients. Two thresholds define a region of hold behavior. Inside that band, the correct action is often to do nothing. Doing nothing is underrated in memory policy design. It is frequently the right answer when uncertainty is high and the system is near equilibrium.
Thrash budget for HBM policy control
The second mechanism is the deterministic safety valve. The thrash budget ledger is a per-epoch counter initialized to a maximum value, with a default around 100 in the simulator. Every discretionary policy action consumes from that budget. Proactive evictions consume budget. Speculative pre-admissions consume budget. Compaction consumes budget. Demand faults still occur, of course, but the point is that the policy cannot keep inventing work for itself forever.
When the budget reaches zero, the system enters fallback mode. In fallback mode, the policy stops doing speculative work. No pre-admission. No proactive compaction. No “maybe this object will be useful later” movement. The runtime falls back to pure demand paging: admit on fault, evict only when necessary to make room, and otherwise stop trying to be clever. At the start of the next epoch, the budget resets and the adaptive behavior is allowed again.
This matters more than it might first appear. In infrastructure teams, the first question about an adaptive policy is not whether it is smart. The first question is whether it is bounded. An operator needs to be able to say, with a straight face, that the policy cannot cause more than some maximum amount of migration or churn per unit time. That is what the thrash ledger buys. It puts a hard ceiling on policy-induced work, even if the forecast is temporarily miscalibrated or the workload is adversarial.
From a control perspective, the thrash budget turns a soft heuristic into a hard guarantee. Instead of trusting the forecast model unconditionally, the system trusts it only until the budget says enough. That is especially important in serving environments where traffic mix can change faster than the modeler expects. A good policy should degrade gracefully under uncertainty. The fallback path is that graceful degradation path.
It is also the piece that made this design feel operationally honest to me. Without the budget, a confidence-driven policy can always be accused, fairly, of hiding unbounded churn behind a probabilistic score. With the budget, the worst-case behavior is explicit. You can tune the aggressiveness of the adaptive mode and still guarantee an upper bound on discretionary churn per epoch. That is the kind of contract platform teams actually deploy.
Safe-window compaction for HBM fragmentation
The third mechanism is compaction, but with a constraint that is more important than the compaction algorithm itself. Compaction physically relocates HBM residents so that multiple smaller free extents collapse into one larger contiguous region. That increases the Largest Free Extent and lowers the external fragmentation ratio. In a simulator, it is easy to treat compaction as a free button. In a real serving stack, it is not. If any in-flight kernel holds a pointer into HBM, moving an object can invalidate that pointer and corrupt the computation.
That is why the HBM Fragmentation Guard never compacts opportunistically in the middle of arbitrary execution. It requires an explicit safe_window signal from the upstream scheduler or runtime. A safe window means that, at this instant, no computation currently in flight depends on stable object addresses in the region being managed. This makes the compaction policy compatible with essentially any attention kernel or serving runtime, because the guarantee comes from the integration boundary rather than from guessing when it is safe.
Compaction is then gated by multiple conditions, not one. The trigger is effectively: compact when external_frag > frag_threshold and LFE < min_contiguous_requirement and the runtime is inside a safe window and the thrash budget still has room. This matters because high fragmentation alone is not always actionable. If your upcoming allocations are small, the right move may be to tolerate fragmentation for a while. Similarly, a low LFE is only urgent if the next resident actually requires a larger contiguous region.
The multi-condition gate keeps compaction from becoming a reflex. Many systems get into trouble because once they detect fragmentation, they start compacting at the first opportunity, regardless of whether compaction is actually needed for the next scheduling decision. That is backwards. Compaction should be treated as a physically disruptive operation that is justified only when allocator shape has become the limiting factor for future work.
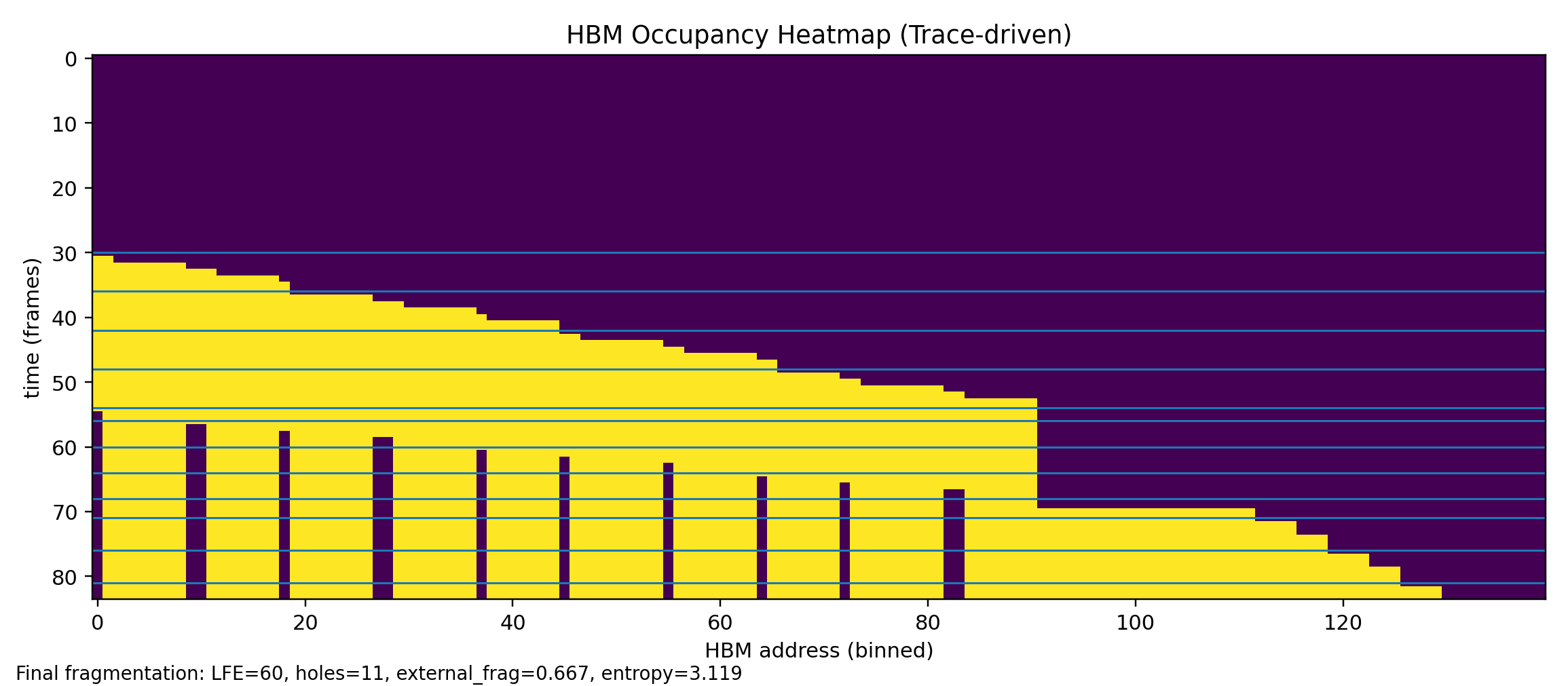
In the simulator this shows up clearly on the fragmentation stressor trace. You can tolerate a surprising amount of hole growth before allocatability truly collapses. The moment that matters is when the largest free extent falls below the size needed for the next meaningful resident. Safe-window compaction is designed around that allocator reality, not around a generic desire to keep the memory map visually tidy.
Fragmentation metrics for HBM allocatability
The fourth mechanism is not a control action but a measurement discipline. The simulator tracks four fragmentation metrics because no single number tells the whole story. The first and most important is LFE, the Largest Free Extent. This is the size in bytes of the biggest contiguous free region. If you need a 2GB resident and your LFE is 312MB, the allocation is dead on arrival regardless of how much total free memory remains elsewhere.
The second metric is holes: the count of distinct free extents. Holes are a coarse but useful indicator of fragmentation growth. A rising hole count tells you that the allocator is no longer dealing with one or two large reusable cavities; it is dealing with many islands. Hole count alone does not tell you which islands matter, but it does tell you whether the shape of free memory is becoming more irregular.
The third metric is the external fragmentation ratio, computed as 1 - LFE / total_free. When this value is zero, all free space is contiguous. When it approaches one, most free bytes are trapped in extents too small to satisfy large allocations. This is a good operational summary because it normalizes LFE by total free memory. Two systems with the same LFE may have very different free-space quality depending on how much total memory is available.
The fourth metric is entropy, the Shannon entropy of free-extent sizes. Entropy matters because two memory maps can have the same external fragmentation ratio and still present very different allocator difficulty. A handful of similarly sized extents behaves differently from a long tail of tiny, irregular extents. High entropy means the free-space landscape is scattered across many sizes, which usually means the allocator has fewer predictable placement options. Entropy therefore acts as an early warning for allocator instability before catastrophic failure shows up in LFE alone.
Together, these metrics let the simulator reason about more than occupancy. Occupancy answers the question “how full is HBM?” Fragmentation metrics answer the more operationally relevant question: “how usable is the free HBM that remains?” In my view, that is the correct lens for modern accelerator memory management.
Benchmark results for the HBM confidence policy
The benchmark harness compares the confidence-gated policy against an LRU demand-paging baseline across the default workload suite. The table below shows representative numbers for the llm_kvcache_growth trace. I am intentionally using moderate, believable deltas rather than giant headline numbers, because the practical point is not that the policy performs miracles. The point is that it preserves allocator shape under pressure well enough to change system behavior at the margin that matters.
| Metric | LRU (demand) | Confidence (demand) | Improvement |
|---|---|---|---|
| Faults | 847 | 501 | −41% |
| Migrations (bytes moved) | 2.3 GB | 0.9 GB | −61% |
| Fallback epochs | 23 | 8 | −65% |
| Final external_frag | 0.74 | 0.27 | −64% |
| Final LFE (MB) | 48 MB | 312 MB | +550% |
| Entropy | 3.82 | 1.44 | −62% |
The first thing to notice is that faults and migration volume both move in the same direction. That is not guaranteed a priori. A badly behaved “smart” policy can easily reduce faults by aggressively pre-admitting objects while increasing migration bytes so much that the cure is worse than the disease. That is not what is happening here. The confidence gate cuts faults by 41% and moved bytes by 61%, which is exactly the shape you want: less miss-induced disruption and less policy-induced churn.
The most important number in the table, however, is not faults. It is LFE. A final Largest Free Extent of 312MB versus 48MB under LRU is the practical difference between still being able to place a new large resident contiguously and being forced into compaction or outright rejection. An allocator does not care that total free memory remains on paper. It cares whether the next object physically fits. A 550% LFE improvement is therefore more operationally meaningful than a similar percentage change in a softer proxy metric.
The fallback epoch reduction tells a stability story. The confidence policy is not merely extracting a bit more hit rate from the same memory. It is spending much less time in degraded, demand-only mode. In other words, the policy is consuming less of its own safety budget. That is exactly what you want from a production-facing adaptive mechanism: fewer emergency epochs, fewer blocked discretionary actions, and a system that stays in its normal control regime longer.
The cross-trace pattern is also encouraging. The fragmentation stressor produces the largest external fragmentation delta, which is what you would expect because the trace is explicitly designed to create scattered holes. The MoE expert swap trace shows the strongest LFE benefit, which also makes sense because forecast-aware residency helps preserve contiguous space in the presence of bursty expert churn. Different traces reward different parts of the design, but all three point in the same direction: preserving HBM shape is at least as important as preserving raw occupancy.
How to run the HBM simulator
The project is intentionally lightweight to run. There is no custom runtime, no special hardware dependency, and no vendor-specific hook required to inspect the policy behavior. The simplest path is to clone the repository, create a virtual environment, install the core requirements, and compare the confidence policy against the LRU baseline directly on the KV-cache trace.
git clone https://github.com/manishklach/hbm_fragmentation_guard_sim
cd hbm_fragmentation_guard_sim
python -m venv .venv && source .venv/bin/activate # or .venv\Scripts\activate on Windows
pip install -r requirements.txt
# Run confidence policy vs LRU on KV-cache growth trace
python run_sim.py --trace traces/llm_kvcache_growth.jsonl --policy confidence --miss-mode demand
python run_sim.py --trace traces/llm_kvcache_growth.jsonl --policy lru --miss-mode demandThe CLI output is a compact simulator summary: faults, migrations, bytes moved, fallback epochs, and fragmentation metrics such as LFE and external fragmentation. When comparing policies, the first two numbers I would look at are LFE and fallback epochs, because together they tell you whether the system is preserving allocator shape without burning its churn budget.
python bench.pyThe benchmark runner prints a multi-policy table that makes the comparison easier to scan. This is the fastest way to get a side-by-side view across the canonical traces and to see whether a change to thresholds or policy behavior improved one metric at the expense of another.
python -m tools.visualize_fragmentation \
--trace traces/fragmentation_stressor.jsonl \
--out docs/img/my_heatmap.pngThe visualizer generates a heatmap of HBM occupancy over time. What you want to watch for is the white-space geometry. A single large free band is healthy. A checkerboard of small white gaps means free memory exists but is becoming progressively less useful for large placements.
Trace format for HBM memory experiments
The simulator consumes newline-delimited JSON events. Each line is an allocation, free, touch, or safe-window marker. The event stream is intentionally simple because I wanted it to be easy to synthesize workloads, import traces from other experiments, and reason about policy behavior without dragging in a large serving stack just to reproduce a memory-control decision.
Here is a compact 10-line example for a KV-cache style scenario:
{"t": 0, "event": "alloc", "id": "kv_req7_blk0", "size": 16777216}
{"t": 1, "event": "touch", "id": "kv_req7_blk0", "mu": 0.88, "sigma": 0.05, "phase": "prefill"}
{"t": 2, "event": "alloc", "id": "act_req7_step0", "size": 524288}
{"t": 3, "event": "touch", "id": "act_req7_step0", "mu": 0.12, "sigma": 0.08, "phase": "prefill"}
{"t": 4, "event": "free", "id": "act_req7_step0"}
{"t": 5, "event": "alloc", "id": "kv_req8_blk0", "size": 16777216}
{"t": 6, "event": "touch", "id": "kv_req8_blk0", "mu": 0.83, "sigma": 0.06, "phase": "decode"}
{"t": 7, "event": "safe_window", "phase": "batch_boundary"}
{"t": 8, "event": "touch", "id": "kv_req7_blk0", "mu": 0.91, "sigma": 0.04, "phase": "decode"}
{"t": 9, "event": "touch", "id": "kv_req8_blk0", "mu": 0.87, "sigma": 0.05, "phase": "decode"}There are three design dimensions worth varying when you build traces. The first is object size distribution. Large KV blocks and expert weights stress contiguity differently from small activation buffers. The second is reuse probability distribution. High-mu hot experts, moderate-mu decode-state blocks, and low-mu one-shot activations exercise very different admission and eviction behavior. The third is safe-window frequency. Dense safe windows make compaction more available; sparse safe windows force the allocator to live with fragmentation longer and therefore stress LFE preservation more severely.
Adding a custom policy is also straightforward. Drop a new implementation into policy/, keep the interface small, and wire it into the registry in run_sim.py. Conceptually, the simulator expects two primary decisions: admit(obj, hbm_state) -> bool and evict(hbm_state) -> obj_id. The current implementation also allows richer policy hooks, but that conceptual interface is enough to think about what a baseline needs to contribute.
Related work on GPU memory policy and fragmentation
PagedAttention in vLLM is the most obvious reference point because it changed how practitioners think about KV-cache allocation. Its main contribution is to solve internal fragmentation in the logical KV representation by paging cache state into smaller units. That is a major improvement, and I would not frame this work as a replacement. The HBM Fragmentation Guard is complementary. PagedAttention improves how cache blocks are represented and managed logically; the fragmentation guard is about which objects get physical HBM residency and how the free physical address space evolves over time.
Strata, from MLSys 2025, is important because it shows that fragmentation harms not only allocator behavior but also data movement efficiency. Its focus is on fragmented I/O between slower tiers and the GPU, using GPU-assisted transfer scheduling to recover throughput that small fragmented transfers would otherwise waste. That sits above the residency problem addressed here. If anything, the two approaches complement each other: one reduces the amount of fragmented traffic you need to move by keeping better residents in HBM, while the other makes unavoidable fragmented transfers less painful.
Marconi, also at MLSys 2025, is the closest in spirit because it uses forecast-based admission for prefix caching in hybrid LLM systems. The overlap is philosophical rather than identical. Both systems argue that admission should be driven by reuse likelihood rather than blind recency. But the control layer is different. Marconi operates at the semantic prefix-cache layer; the HBM Fragmentation Guard operates at physical HBM residency. The same forecasting mindset is being used to answer different questions at different granularities.
Classic page replacement policies still matter as baselines. LRU remains the de facto default in many serving systems simply because it is easy to reason about and easy to implement. CLOCK-Pro improves on LRU by maintaining hot and cold distinctions, and that is why I added it as a baseline to the simulator. But neither LRU nor CLOCK-Pro has a probabilistic reuse forecast, and neither carries a deterministic thrash budget safety mechanism. They are missing exactly the two pieces I think matter for practical deployment under highly nonstationary AI workloads.
HiFC and related flash-based KV-cache swapping systems attack yet another adjacent problem: capacity extension beyond HBM into slower tiers such as NVMe. That is a valuable direction, but it is solving a different bottleneck. The HBM Fragmentation Guard does not try to create more capacity. It tries to preserve the usefulness of the HBM capacity you already have. In that sense, a flash offload system and a physical HBM residency controller can coexist naturally in a layered design.
The HBM Fragmentation Guard fills a specific gap: a software-layer policy that operates at the physical HBM residency level, below the serving framework and above the hardware, with a deterministic safety mechanism that makes it deployable in production without per-workload tuning.
Conclusion on HBM confidence policy and next steps
The design comes down to three ideas that reinforce each other. First, use a confidence gate rather than pure recency so HBM admission and eviction reflect actual reuse likelihood. Second, wrap that adaptive behavior in a thrash budget so the worst-case churn is explicitly bounded. Third, allow compaction only inside safe windows so allocator repair never races in-flight computation. Together, those mechanisms turn fragmentation control from a reactive allocator problem into an explicit systems policy.
The simulator is MIT-licensed and intended for research and engineering evaluation. The patent application is pending with the Indian Patent Office. The immediate next steps are clear: add a CLOCK-Pro baseline for a fuller three-way comparison, add a Streamlit dashboard for interactive parameter sweeps, and replace the current mock traces with real HBM access traces captured from HuggingFace Transformers inference sessions. If this is useful for your work, star the repository, open an issue with your workload trace, or cite the included CITATION.cff in research use.